Debianで稼働するLinuxサーバでメッセージ「SMART error (CurrentPendingSector) detected on host: %HOSTNAME%」が届いたのでご報告です。
RAID1で運用していたHDDに問題が発生したようでした。
アラートメールを受け取る
最初に受信したのは平日の朝。
そのメールには件名に、
SMART error (CurrentPendingSector) detected on host: %HOSTNAME%
と記載されていました。
本文には、(一部抜粋)
--------------------------------------------------------------
The following warning/error was logged by the smartd daemon:
Device: /dev/sdb [SAT], 3 Currently unreadable (pending) sectors
Device info:
WDC WD2500AAKX-193CA0, S/N:WD-WMAYWxxxxxxx, WWN:5-0014ee-00361267d
For details see host's SYSLOG.
You can also use the smartctl utility for further investigation.
--------------------------------------------------------------
次の警告/エラーがsmartdデーモンによってログに記録されました。
デバイス:/ dev / sdb [SAT]、現在読み取り不可能な(保留中の)セクター
デバイス情報:WDC WD2500AAKX-193CA0、
詳細については、ホストのSYSLOGを参照してください。
さらに調査するためにsmartctlユーティリティを使用することもできます。
--------------------------------------------------------------
ちなみに「Currently unreadable (pending) sectors」の箇所が「Offline uncorrectable sectors」となったエラーメールも受信しており、エラーメールとしてはこの不達がペアになっているようでした。
システムディスクとして利用しているサーバのHDDでセクタ異常が発生したようでした。
ログと動作を調べる
メッセージに沿ってsyslogを中心にログを確認してみることにします。
syslogを確認したところ、以下の三行が繰り返し出力されていることが分かりました。
--------------------------------------------------------------
smartd[444]: Device: /dev/sdb [SAT], 3 Currently unreadable (pending) sectors
smartd[444]: Device: /dev/sdb [SAT], 3 Offline uncorrectable sectors
smartd[444]: Device: /dev/sdb [SAT], SMART Usage Attribute: 194 Temperature_Celsius changed from 100 to 101
--------------------------------------------------------------
"uncorrectable sectors"=「修正不可能なセクター」とか、"unreadable (pending) sectors"=「読み取り不可能な(保留中の)セクター」といったエラーメッセージから、HDDのセクタ異常に端を発したエラーということはほぼ間違いないようです。
ただし、救いなのは、
--------------------------------------------------------------
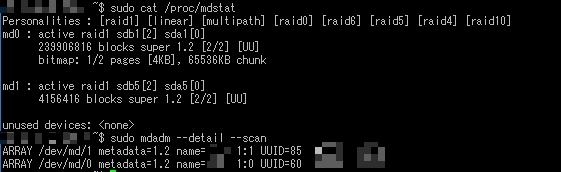
$ sudo cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md1 : active raid1 sdb5[2] sda5[0]
4156416 blocks super 1.2 [2/2] [UU]
md0 : active raid1 sdb1[2] sda1[0]
239906816 blocks super 1.2 [2/2] [UU]
bitmap: 0/2 pages [0KB], 65536KB chunk
unused devices: <none>
--------------------------------------------------------------
RAID1で構成していたエラー対象のディスクが生きている(mdデバイスで"[2/2] [UU]"と表示されている)ことです。幸いなことに、使われていない領域(データが書き込まれていない領域)で発生した不良セクタのようで、現状のサーバ稼働に致命的なダメージを与えていないようでした。問題のsdbが含まれるアレイは正常稼働中。
この後「$ sudo smartctl -t short /dev/sdb」や「$ sudo smartctl -l salftest /dev/sdb」で確認してみたものの、故障したらしいという情報以外は特に得られず。
故障が/dev/sdbというのは不幸中の幸いでした。RAID1のスレーブ側なので、ディスク交換後にRAID1の再構築だけで作業は済みそうです。
ディスク交換作業:物理交換前
作業日当日、Hyper-Vの仮想OSでリハーサルもやったし、万全の状態で当日を迎えることができました。
さっそく、サーバのディスクを取り外します。mdadmコマンドの--failオプションで障害状態に移行させます。
mdadm /dev/md0 --fail /dev/sdb1
mdadm /dev/md1 --fail /dev/sdb5
その後fail状態に移行したディスクを、RAIDのmd0/1から取り外します。
mdadm /dev/md0 --remove /dev/sdb1
mdadm /dev/md1 --remove /dev/sdb5
ここまでで、各mdデバイスにステータスが(cat /proc/mdstatコマンドで見ると)
--------------------------------------------------------------
md1 : active (auto-read-only) raid1 sda5[0]
4156416 blocks super 1.2 [2/1] [U_]
md0 : active raid1 sda1[0]
239906816 blocks super 1.2 [2/1] [U_]
bitmap: 2/2 pages [8KB], 65536KB chunk
--------------------------------------------------------------
このように正常時"[2/2] [UU]"とあった表記が"[2/1] [U_]"と変化します。failとremoveでディスクがmdデバイスから脱退し、縮退運転状態にあることが分かります。いちおう「mdadm --detail --scan」コマンドや「fdisk -l」でディスクの情報収集をして、OSをシャットダウン。
ディスク交換作業:物理交換
シャットダウンしたサーバ本体から、故障したディスクを取り外すのですが、念には念を入れて、正常動作していた/dev/sdaのディスクもデュプリケータでバックアップしておくことにしました。
ディスクのシリアル番号を確認しながら、正常動作しているディスクとエラーが発生したディスクを取り違えないよう慎重に取り扱います。
ディスク交換作業:物理交換後
バックアップした/dev/sdaディスクを元通り設置、故障した/dev/sdbディスクは予備ディスク(この予備ディスクはパーティショニングやフォーマットがされていない削除状態)と交換し、本体に接続していきます。
※ディスクは同一メーカの同一型番/同容量のディスクを予備ディスクとして用意しています。
再び、電源を投入しサーバOSを起動。
cat /proc/mdstat
にて、シャットダウン前と同じ状態出あることを確認(加えて"cat /var/log/syslog | grep sd | less"でディスクが認識しているという点も念のため確認)した後、
fdisk -l
でディスク情報を確認しました。/dev/sdbがしっかり認識していることを確認したら、
fdisk /dev/sdb
にてパーティションを作成していきます。作成するパーティションは構築時に残したドキュメントを参照して、同じセクタ数を指定することでRAID1の準備ができました。
RAID1のリビルドを実行するため、mdデバイスに新しいsdbを参加させます。
mdadm /dev/md0 --add /dev/sdb1
mdadm /dev/md1 --add /dev/sdb5
実行後、"cat /proc/mdstat"でリビルドの進捗を確認します。
画面には
--------------------------------------------------------------
md0 : active raid1 sdb1[2] sda1[0]
239906816 blocks super 1.2 [2/1] [U_]
[>....................] recovery = 0.8% (1928064/239906816) finish=70.3min speed=56398K/sec
bitmap: 2/2 pages [8KB], 65536KB chunk
md1 : active raid1 sdb5[2] sda5[0]
4156416 blocks super 1.2 [2/1] [U_]
resync=DELAYED
--------------------------------------------------------------
このように、リビルドが進捗していきます。
md0とmd1は順番にリビルドが実行されるので、気長に待ちます。上記ではmd0が完了後md1のリビルドが始まります。
md0とmd1の両方のリビルドが完了したところで対処完了。
無事ディスク交換が完了しました。
後処理
RAID1で同期したディスクですが、交換したsdb側にはgrubブートローダーをインストールする必要があります。※これをやっていないと、sdaに障害が発生したときにいざsdbに交換してもOSが起動しないということになります。
grub-install /dev/sdb
update-grub
を実行して、
--------------------------------------------------------------
# grub-install /dev/sdb
Installing for i386-pc platform.
Installation finished. No error reported.
# update-grub
Generating grub configuration file ...
Linux イメージを見つけました: /boot/vmlinuz-3.16.0-4-686-pae
Found initrd image: /boot/initrd.img-3.16.0-4-686-pae
完了
--------------------------------------------------------------
特にエラーも出なかったし、大丈夫だろう、ということで、対処は完了。
なんとかDebianサーバの故障したハードディスク交換を無事完了させ、稼働まで復旧差せることができました。